
Korištenje programa IBM SPSS Modeler pri sprječavanju odlaska klijenata
Kada koristimo IBM SPSS Modeler za sprječavanje odlaska klijenata, slijedimo CRISP-DM metodologiju, koja analitiku dijeli u pet koraka:
- Razumijevanje poslovnog područja: prije nego krenemo praviti model, analitičar mora razumjeti poslovno područje i poslovni problem koji obrađuje. Kada se odlaskom klijenata bavite sami, možete preskočiti ovaj korak. Kada analitiku povjerite u ruke vanjskim analitičarima, morate biti sigurni da poznaju područje vašeg rada i da će pravilno postaviti model te izračunati vjerovatnoću odlazaka.
- Razumijevanje podataka: da bi dobili pravilne vjerovatnoće odlazaka klijenata, moramo u prediktivni model dovesti pravilne i kvalitetne podatke o odlasku klijenata iz prethodnih godina. Ti podaci imaju veliki uticaj na naše krajnje rezultate, budući da svaki podatak ima utiacaj na logiku modela, koji će izraditi program.
- Priprema podataka: da bi dobili željeni skup podataka, moramo prikupiti podatke iz različitih izvora. Ako imamo na raspolaganju skladište podataka, tim bolje, jer u tom slučaju koristimo jedan izvor. No, najčešće se je za pravi skup potrebno malo više potruditi i potražiti po tabelama i bazama, koje se nalaze svugdje po kompaniji. U takvom slučaju, te baze uvozimo u IBM SPSS Modeler te ih se sa raspoloživim ETL alatima pregledamo, agregiramo i obradimo. Rezultat je jedan skup podataka, koji će nam služiti kao osnova prediktivnog modela.
- Modeliranje: cijeli proces prediktivne analitike se odvija preko prediktivnih modela koje izrađujemo u programu IBM SPSS Modeler. Program podržava algoritme za klasifikaciju, što su klasični prediktivni algoritmi, kao i korištenje modela za asocijaciju te segmentaciju. Budući da IBM SPSS Modeler koriste i osobe koje nisu stručnjaci, dostupan je i automatski odabir algoritma, koji među svim raspoloživim algoritmima ponudi onaj koji će najtačnije izračunati koji klijenti vas namjeravaju napustiti.
- Ocjenjivanje tačnosti: podatke koje smo dobili u prijašnjim koracima, provedemo kroz model. Model će pregledati podatke iz prošlosti i pokušati naći uzorke i veze na osnovu kojih će pripremiti poslovna pravila za određivanje odlaska klijenata. U tu svrhu skup podataka razdijelimo na dva dijela – testni dio i dio za učenje. Drugi dio se koristi za učenje modela. Kada proces učenja završi, kroz model provedemo testni dio i omjer onih koji će ostati i onih koji će otići mora biti jednak.
- Korištenje modela: Kada smo zadovoljni sa modelom, spremni smo za korištenje u praksi. Kroz prediktivni model provedemo svježe podatke, koji pokrivaju sve naše trenutne, aktivne klijente. Prediktivni model će za svakog klijenta izračunati vjerovatnoću odlaska, rezultati su grafički predstavljeni kako bi odabir kandidata za dalju obradu bio jednostavniji. Kada za svakog klijenta dobijemo vjerovatnoću odlaska, nećemo se baviti sa svima, već sa onima, koji s jedne strane imaju najveću vrijednost za nas, a s druge strane imaju najveću vjerovatnoću da će otići.
Rezultati
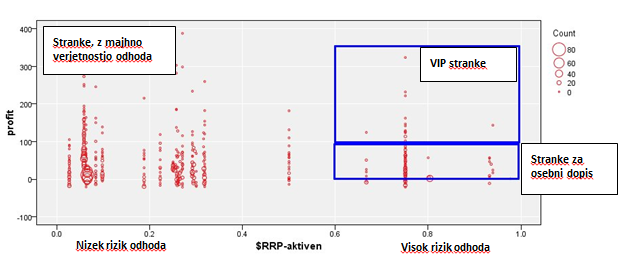
Na gornjoj slici je na osi X prikazana vjerovatnoća odlaska, a njihova vrijednost za kompaniju na osi Y. Kada ograničimo kampanju na zadržavanja klijenata, istovremeno smanjujemo troškove i povećavamo učinkovitost.
Bazu ćemo podijeliti u tri segmenta:
- Klijenti koje ne uznemiravamo: oni koji imaju nizak rizik odlaska ili oni koji imaju premalu vjerovatnoću da bi se s njima bavili.
- VIP klijenti sa velikom vrijednošću za nas i visokom vjerovatnoćom odlaska. Takve klijente uvijek tretiramo individualno, kontaktiramo ih i pozivamo na sastanak.
- Pristup ličnim dopisom – ostalim klijentima šaljemo smislen dopis koji će odgovarati njihovim karakteristika i preferencijama.